Further Thoughts on How to Track Versions with MongoDB
GUEST POST by Paul Done
In a previous Ask Asya blog post, Asya outlined various approaches for preserving historical versions of records for auditing purposes, whilst allowing current versions of records to be easily inserted and queried. Having found the post to be extremely useful for one of my projects, and following some further investigations of my own, I realised that two of the choices could be refined a little to be more optimal. Upon feeding back my findings, Asya graciously asked me to document them here, so here goes.
Revisit of Choice 2 (Embed Versions in a Single Document)
The presented ‘compare-and-swap’ example code, to generate a new version and update version history, is very effective at ensuring consistency of versions in a thread-safe manner. However, I felt that there was scope to reduce the update latency which will be particularly high when a document has grown, with many previous versions embedded.
For example, if a current document has tens of embedded previous versions, then projecting the whole document back to the client application, updating part of the document copy and then sending the whole document as an update to the database, will be slower than necessary. I prototyped a refactored version of the example code (shown below) which exhibits the same functional behaviour, but avoids projecting the entire document and uses an in-place update to push changes to the database.
Don’t return all the old versions:
var doc = db.coll.findOne({"_id": 174}, {"prev": 0});
var currVersion = doc.current.v;
var previous = doc.current;
var current = {
"v" : currVersion+1,
"attr1": doc.current.attr1,
"attr2": "YYYY"
};
Perform in-place update of changes only:
var result = db.coll.update(
{ "_id" : 174, "current.v": currVersion},
{ "$set" : {"current": current},
"$push" : {"prev": previous}
}
);
if (result.nModified != 1) {
print("Someone got there first, replay flow to try again");
}
As a result, even when the number of versions held in a document increases over time, the update latency for adding a new version remains roughly constant.
Revisit of Choice 3 (Separate Collection for Previous Versions)
The original post implies that this choice is technically challenging to implement, to ingest a new document version whilst maintaining consistency with previous versions, in the face of system failure. However, I don’t feel it’s that bad, if the update flow is crafted carefully. If the order of writes is implemented as “write to previous collection before writing to current collection”, then in a failure scenario, there is potential for a duplicate record version but not a lost record version. Also, there are ways for subsequent querying code to gracefully deal with the duplicate.
If the following three principles are acceptable to an application development team, then this is a viable versioning option and doesn’t have the implementation complexity of choice 5, for example:
System failure could result in a duplicate version, but not a lost version.
Any application code that wants to query all or some versions of the same entity, is happy to issue two queries simultaneously, one against the current collection (to get the current version) and one against the previous collection (to get historic versions), and then merge the results. In cases where a duplicate has been introduced (but not yet cleaned up - see next point), the application code just has to detect that the latest version in the current collection also appears as a record in the previous collection. When this occurs, the application code just ignores the duplicate, when constructing its results. In my experience, most ‘normal’ queries issued by an application, will just query the current collection and be interested in latest versions of entities only. Therefore this ‘double-query’ mechanism is only needed for the parts of an application where historic version analysis is required.
The next time a new version of a document is pushed into the system, the old duplicate in the previous collection (if the duplicate exists) will become a genuine previous version. The current collection will contain the new version and the previous collection will only contain previous versions. As a result, there is no need for any background clean up code mechanisms to be put in place.
For clarity, I’ve included a JavaScript example of the full update flow below, which can be run from the Mongo shell.
//
// CREATE SAMPLE DATA
//
db.curr_coll.drop();
db.prev_coll.drop();
db.curr_coll.ensureIndex({"docId" : 1}, {"unique": true});
db.prev_coll.ensureIndex({"docId" : 1, "v" :1}, {"unique": true});
db.curr_coll.insert([
{"docId": 174, "v": 3, "attr1": 184, "attr2": "A-1"},
{"docId": 133, "v": 3, "attr1": 284, "attr2": "B-1"}
]);
db.prev_coll.insert([
{"docId": 174, "v": 1, "attr1": 165},
{"docId": 174, "v": 2, "attr1": 165, "attr2" : "A-1"},
{"docId": 133, "v": 1, "attr1": 265},
{"docId": 133, "v": 2, "attr1": 184, "attr2" : "B-1"}
]);
//
// EXAMPLE TEST RUN FLOW
//
// UPSERT (NOT INSERT) IN CASE FAILURE OCCURED DURING PRIOR ATTEMPT.
// THE PREV COLLECTION MAY ALREADY CONTAIN THE 'OLD' CURRENT VERSION.
// IF ALREADY PRESENT, THIS UPSERT WILL BE A 'NO-OP', RETURNING:
// nMatched: 1, nUpserted: 0, nModified: 0.
var previous = db.curr_coll.findOne({"docId": 174}, {_id: 0});
var currVersion = previous.v;
var result = db.prev_coll.update(
{"docId" : previous.docId, "v": previous.v },
{ "$set": previous }
, {"upsert": true});
// <-- STOP EXECUTION HERE ON A RUN TO SIMULATE FAILURE, THEN RUN
// FULL FLOW TO SHOW HOW THINGS WILL BE NATURALLY CLEANED-UP
// UPDATE NEW VERSION IN CURR COLLECTION, USING THREAD-SAFE VERSION CHECK
var current = {"v": currVersion+1, "attr1": previous.attr1, "attr2":"YYYY"};
var result = db.curr_coll.update({"docId": 174, "v": currVersion},
{"$set": current}
);
if (result.nModified != 1) {
print("Someone got there first, replay flow to try again");
}
//
// EXAMPLE VERSION HISTORY QUERY CODE
//
// BUILD LIST OF ALL VERSIONS OF ENTITY, STARTING WITH CURRENT VERSION
var fullVersionHistory = [];
var latest = db.curr_coll.findOne({"docId": 174}, {_id: 0});
var latestVersion = latest.v;
fullVersionHistory.push(latest);
// QUERY ALL PREVIOUS VERSIONS (EXCLUDES DUPLICATE CURRENT VERSION IF EXISTS)
var previousVersionsCursor = db.prev_coll.find({
"$and": [
{"docId": 174},
{"v": {"$ne": latestVersion}}
]
}, {_id: 0}).sort({v: -1});
// ADD ALL THESE PREVIOUS VERSIONS TO THE LIST
previousVersionsCursor.forEach(function(doc) {
fullVersionHistory.push(doc);
});
// DISPLAY ALL VERSIONS OF AN ENTITY (NO DUPLICATES ARE PRESENT)
printjson(fullVersionHistory);
As a result of this approach, it is easy to query current versions of entities, easy to query the full version history of a given entity and easy to update an entity with a new version.
In Summary
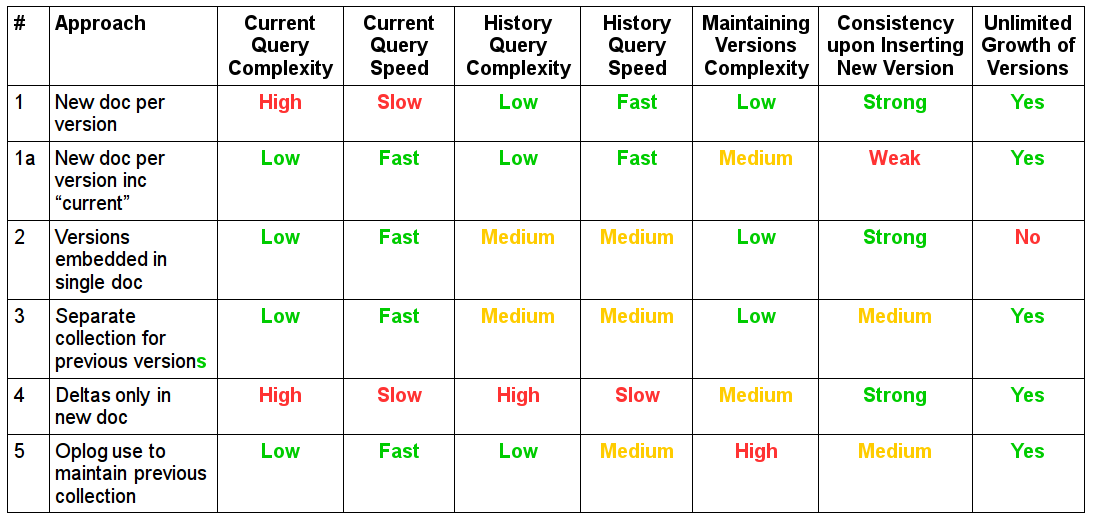
I’ve taken the liberty of providing a modified version of Asya’s summary table below, to expand out the criteria that may be relevant when choosing a versioning strategy for a given use case. My version of the table also reflects the improved results for choices 2 and 3, on the back of what has been discussed in this blog post.
Updated Table of Tradeoffs:
 .
.